
Ablation Studies in Sentiment Analysis: Impact of LLM Roles and Consensus
:::info
Authors:
(1) Xiaofei Sun, Zhejiang University;
(2) Xiaoya Li, Shannon.AI and Bytedance;
(3) Shengyu Zhang, Zhejiang University;
(4) Shuhe Wang, Peking University;
(5) Fei Wu, Zhejiang University;
(6) Jiwei Li, Zhejiang University;
(7) Tianwei Zhang, Nanyang Technological University;
(8) Guoyin Wang, Shannon.AI and Bytedance.
:::
Table of Links
Abstract and Intro
Related Work
LLM Negotiation for Sentiment Analysis
Experiments
Ablation Studies
Conclusion and References
5 Ablation Studies
In this section, we perform ablation studies on the Twitter dataset to better understand the mechanism behind the negotiation framework.
\
\
5.1 Who takes which role matters
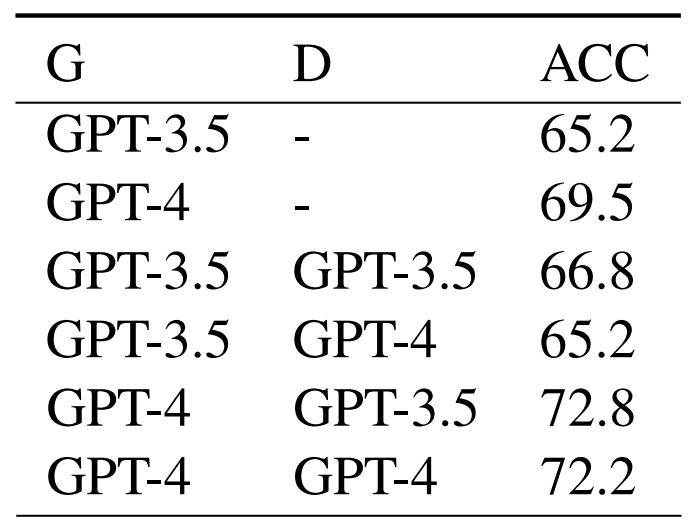
In the negotiation framework, there are two roles, the generator and the discriminator, which two separate LLMs take. Table 2 shows the performance for setups where GPT-3.5 and GPT-4 take different roles.
\
As can be seen, when GPT-3.5 acts as the generator, and GPT-4 acts as the discriminator (G3.5-D4 for short), the performance (68.8) is better than single GPT-3.5 without negotiation (65.2), but worse than single GPT-4 without negotiation (69.5). In contrast, negotiation-based configurations with GPT-4 acting as the generator (G4-D3.5 and G4-D4) consistently outperforms standalone GPT-4 or GPT-3.5 models without negotiation. These results underscore the pivotal role that the generator plays in influencing the negotiation outcome. Furthermore, we observe G4- D3.5 can beat G4-D4. We attribute such advantage to the hypothesis that utilizing heterogeneous LLMs for distinct roles could optimize the negotiation’s performance.
5.2 Consensus Percentage
Table 3 consensus percentage for different setups. As can be seen, when GPT-4 acts as the generator, the negotiation is more likely to reach a consensus, or reach a consensus in fewer turns. The explanation is intuitive: for the twitter task, we can see from table 1 that GPT-4 obtains better performances that GPT-3.5, which means the reasoning process for GPT-4 is more sensible than 3.5, making the decision of the former more likely to be agreed on.
\
5.3 Effect of the Reasoning Process
In the negotiation process, LLMs are asked to articulate the reason process, a strategy akin to CoT(Wei et al., 2022b). We examine the importance for listing reasons in negotiation by removing the reasoning process and asking LLMs to only output decisions. Results are shown in Table 4. As can be seen, for the three setups, single GPT-3.5, where only GPT-3.5 is used without negotiation, single GPT-4, where only GPT-4 is used without negotiation, and GPT-3.5+GPT-4 where negotiation is employed, performances all degrade when the reasoning process is removed. But interestingly, we see a greater degrade (-2.3) for the negotiation than the single model setup (-1.2 for single-GPT-3.5 and -0.9 for single-GPT-4). This is in accord with our expectation as the reasoning process is of greater significance in the negotiation setup.
\
:::info
This paper is available on arxiv under CC 4.0 license.
:::
\
Welcome to Billionaire Club Co LLC, your gateway to a brand-new social media experience! Sign up today and dive into over 10,000 fresh daily articles and videos curated just for your enjoyment. Enjoy the ad free experience, unlimited content interactions, and get that coveted blue check verification—all for just $1 a month!
Account Frozen
Your account is frozen. You can still view content but cannot interact with it.
Please go to your settings to update your account status.
Open Profile Settings